Animal Kingdom Dataset
 This is the official repository for
This is the official repository for
[CVPR2022] Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding
Xun Long NG, Kian Eng ONG, Qichen ZHENG, Yun NI, Si Yong YEO, Jun LIU
Information Systems Technology and Design, Singapore University of Technology and Design, Singapore
Dataset and Codes
Download dataset and codes here
NOTE: The codes of the models for all tasks have been released. Codes are included in the folder of the dataset. After you download our dataset, you can find the corresponding codes for each task. Helper scripts are provided to automatically set up the environment to directly run our dataset. The Animal_Kingdom GitHub codes are the same as the codes in the download version, hence there is no need to download the GitHub codes.
README
Please read the respective README files in Animal_Kingdom for more information about preparing the dataset for the respective tasks.
- Overview of dataset
- Meta-data: 140 Action Description, List of >850 animals and classification
- Action Recognition
- Pose Estimation
- Video Grounding
Paper
Citation
@InProceedings{
Ng_2022_CVPR,
author = {Ng, Xun Long and Ong, Kian Eng and Zheng, Qichen and Ni, Yun and Yeo, Si Yong and Liu, Jun},
title = {Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {19023-19034}
}
Abstract
Understanding animals’ behaviors is significant for a wide range of applications. However, existing animal behavior datasets have limitations in multiple aspects, including limited numbers of animal classes, data samples and provided tasks, and also limited variations in environmental conditions and viewpoints. To address these limitations, we create a large and diverse dataset, Animal Kingdom, that provides multiple annotated tasks to enable a more thorough understanding of natural animal behaviors. The wild animal footages used in our dataset record different times of the day in extensive range of environments containing variations in backgrounds, viewpoints, illumination and weather conditions. More specifically, our dataset contains 50 hours of annotated videos to localize relevant animal behavior segments in long videos for the video grounding task, 30K video sequences for the fine-grained multi-label action recognition task, and 33K frames for the pose estimation task, which correspond to a diverse range of animals with 850 species across 6 major animal classes. Such a challenging and comprehensive dataset shall be able to facilitate the community to develop, adapt, and evaluate various types of advanced methods for animal behavior analysis. Moreover, we propose a Collaborative Action Recognition (CARe) model that learns general and specific features for action recognition with unseen new animals. This method achieves promising performance in our experiments.
Action Recognition

| mAP | ||||
| Method | overall | head | middle | tail |
| Baseline (Cross Entropy Loss) | ||||
| I3D | 16.48 | 46.39 | 20.68 | 12.28 |
| SlowFast | 20.46 | 54.52 | 27.68 | 15.07 |
| X3D | 25.25 | 60.33 | 36.19 | 18.83 |
| Focal Loss | ||||
| I3D | 26.49 | 64.72 | 40.18 | 19.07 |
| SlowFast | 24.74 | 60.72 | 34.59 | 18.51 |
| X3D | 28.85 | 64.44 | 39.72 | 22.41 |
| LDAM-DRW | ||||
| I3D | 22.40 | 53.26 | 27.73 | 17.82 |
| SlowFast | 22.65 | 50.02 | 29.23 | 17.61 |
| X3D | 30.54 | 62.46 | 39.48 | 24.96 |
| EQL | ||||
| I3D | 24.85 | 60.63 | 35.36 | 18.47 |
| SlowFast | 24.41 | 59.70 | 34.99 | 18.07 |
| X3D | 30.55 | 63.33 | 38.62 | 25.09 |
Collaborative Action Recognition (CARe) Model
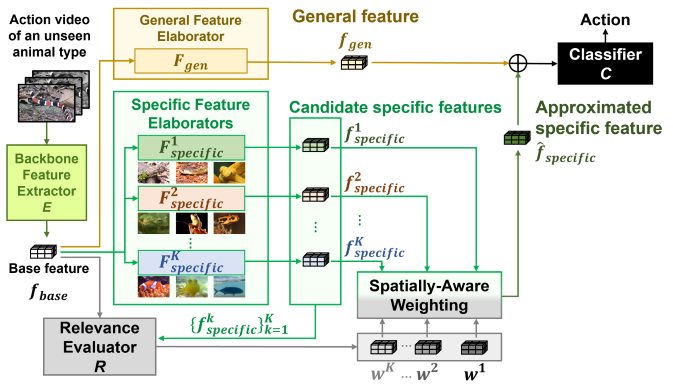
| Method | Accuracy (%) |
| Episodic-DG | 34.0 |
| Mixup | 36.2 |
| CARe without specific feature | 27.3 |
| CARe without general feature | 38.2 |
| CARe without spatially-aware weighting | 37.1 |
| CARe (Our full model) | 39.7 |
Pose Estimation

|
|
PCK@0.05 | ||
| Protocol | Description | HRNet | HRNet-DARK |
| Protocol 1 | All | 66.06 | 66.57 |
| Protocol 2 | Leave-k-out | 39.30 | 40.28 |
| Protocol 3 | Mammals | 61.59 | 62.50 |
| Amphibians | 56.74 | 57.85 | |
| Reptiles | 56.06 | 57.06 | |
| Birds | 77.35 | 77.41 | |
| Fishes | 68.25 | 69.96 | |
Video Grounding

| Recall@1 | mean IoU | ||||
| Method | IoU=0.1 | IoU=0.3 | IoU=0.5 | IoU=0.7 | |
| LGI | 50.84 | 33.51 | 19.74 | 8.94 | 22.90 |
| VSLNet | 53.59 | 33.74 | 20.83 | 12.22 | 25.02 |
Acknowledgement and Contributors
This project is supported by AI Singapore (AISG-100E-2020-065), National Research Foundation Singapore, and SUTD Startup Research Grant.
We would like to thank the following contributors for working on the annotations and conducting the quality checks for video grounding, action recognition and pose estimation.
- Ang Yu Jie
- Ann Mary Alen
- Cheong Kah Yen Kelly
- Foo Lin Geng
- Gong Jia
- Heng Jia Ming
- Javier Heng Tze Jian
- Javin Eng Hee Pin
- Jignesh Sanjay Motwani
- Li Meixuan
- Li Tianjiao
- Liang Junyi
- Loy Xing Jun
- Nicholas Gandhi Peradidjaya
- Song Xulin
- Tian Shengjing
- Wang Yanbao
- Xiang Siqi
- Xu Li